隨著生成式 AI 快速滲透企業與個人應用場景,一個過去未被充分重視的資安風險正逐漸浮上檯面。SentinelOne 旗下 SentinelLABS 與資安搜尋引擎 Censys 最新聯合調查指出,全球已有超過 17.5 萬台 Ollama AI 伺服器直接暴露在公網之上,分布橫跨 130 個國家,形成一層「未受管理、未納管的 AI 算力基礎設施」。
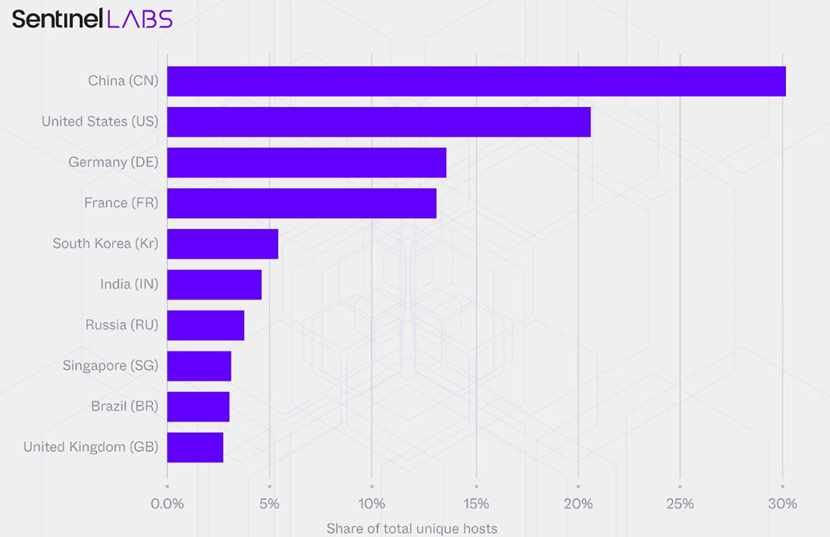
研究團隊指出,這些 Ollama 主機遍布雲端與住宅網路環境,卻普遍未納入企業既有的資安防護、監控與治理機制之中。其中,中國的曝險比例最高,佔整體約三成;其他基礎設施規模較大的國家則包括美國、德國、法國、南韓、印度、俄羅斯、新加坡、巴西與英國。
Ollama 本身是一套開源框架,讓使用者能在 Windows、macOS 與 Linux 環境中,快速下載、執行與管理大型語言模型(LLM)。雖然其預設僅綁定在本機位址(127.0.0.1:11434),但只要進行極為簡單的設定變更,將服務綁定至 0.0.0.0 或對外網卡,就可能在無任何驗證機制的情況下,直接對整個網際網路開放。
問題的關鍵不只在於「暴露」,而在於「能力」。研究顯示,近半數(約 48%)的 Ollama 主機啟用了 Tool Calling(工具呼叫)能力,可透過 API 直接執行程式碼、存取外部 API,甚至與其他系統互動。研究人員 Gabriel Bernadett-Shapiro 與 Silas Cutler 指出,這代表 LLM 已不再只是「生成文字」,而是實際被嵌入更大的系統流程中,能夠把指令轉化為行動。
這也徹底改變了威脅模型。研究團隊直言:「純文字生成端點,頂多產出不當內容;但具備工具呼叫能力的端點,卻可能直接執行具權限的操作。」在缺乏身分驗證、同時又暴露於公網的情況下,這已構成目前 AI 生態系中最高風險等級的資安情境。
調查同時發現,部分主機支援推理(reasoning)、視覺(vision)等進階模型能力,甚至有 201 台主機使用移除安全護欄的 uncensored prompt 模板,進一步放大濫用與攻擊風險。
在這樣的背景下,「LLMjacking(大型語言模型劫持)」不再只是理論。攻擊者可直接濫用受害者的 AI 算力資源,用於產生垃圾郵件、散播假訊息、加密貨幣挖礦,甚至將存取權限轉售給其他犯罪集團,而成本與風險卻完全由受害者承擔。
Pillar Security 本週公布的另一份報告也印證了這一點。研究指出,攻擊者已發動名為 Operation Bizarre Bazaar 的行動,系統性掃描未設防的 Ollama、vLLM 與相容 OpenAI API 的服務端點,驗證其可用性後,再以折扣價對外販售。整個地下服務鏈包含三個環節:大規模掃描、端點驗證,以及透過 silver[.]inc 這類「統一 LLM API 閘道」進行商業化轉售。
研究人員 Eilon Cohen 與 Ariel Fogel 指出,這是首度被完整歸因的 LLMjacking 地下市場,相關行動已追蹤至威脅行為者 Hecker(亦稱 Sakuya、LiveGamer101)。
更值得警惕的是,Ollama 生態系高度分散,且大量部署於住宅網路與邊緣環境,不僅加劇治理困難,也為提示詞注入(prompt injection)、惡意流量代理等攻擊手法,提供了新的跳板。
研究團隊最後強調,隨著 LLM 持續向邊緣端部署,並被用來「把指令轉化為實際行動」,防禦思維必須同步進化。任何可對外存取的 AI 服務,都應被視為正式的關鍵基礎設施,同樣需要落實身分驗證、存取控管、持續監控與網路分段,而不應再被誤認為只是單純的開發工具或實驗性服務。
在生成式 AI 加速落地的同時,如何避免「AI 先上線、資安後補救」,將是企業與組織無法迴避的下一個資安考題。